
Comandi Rapidi ed Ollama: le basi
Ho già mostrato in precedenti articoli l’utilizzo di Ollama su Mac, mi sono tuttavia soffermato solo su 2 aspetti: l'utilizzo a riga di comando con il comando llm o l’utilizzo con un sistema a chat, in stile chatGPT, attraverso OpenWeb UI.
Esiste una terza via che sto utilizzando e di cui ti voglio parlare in questo articolo: le API di Ollama e Comandi rapidi.
1. Cosa sono le API?
API è l'acronimo per application programming interface in italiano "interfaccia di programmazione dell'applicazione" (fonte wikipedia). È uno dei sistemi su cui si basano le applicazioni web e, per quanto ci riguarda, lo strumento che ci permetterà di far dialogare Ollama con Comandi Rapidi.
Non è mia intenzione spiegare nel dettaglio il funzionamento delle richieste alle API, sarebbe argomento troppo complesso e che io non padroneggio sufficientemente bene.
Qui bastata sapere che abitualmente per dialogare con le API di un determinato programma web si posso utilizzare due ”metodi”: GET e POST.
- GET: serve per recuperare dati / informazioni dall’applicativo web,
- POST: serve per porre “domande” all'applicativo web e ricevere dallo stesso risposte.
Ollama tra le altre cosa, una volta installato, fornisce delle REST API che permetto di dialogare con gli LLM installati via web.
Piccola nota a margine: sia quando si utilizza il comando
llmche l’interfaccia web OpenWeb UI di fatto si utilizza il sistema di Rest API di Ollama.
2. Come interfacciarsi con le API attraverso Comandi Rapidi
Spiegato quindi cosa sono le API, vediamo come è possibile utilizzarle attraverso Comandi Rapidi.
2.1 Azione ottieni contenuti dell'URL
Per utilizzare le API di una qualsiasi applicazione web occorre utilizzare l’azione: Ottieni contenuti dell’URL.
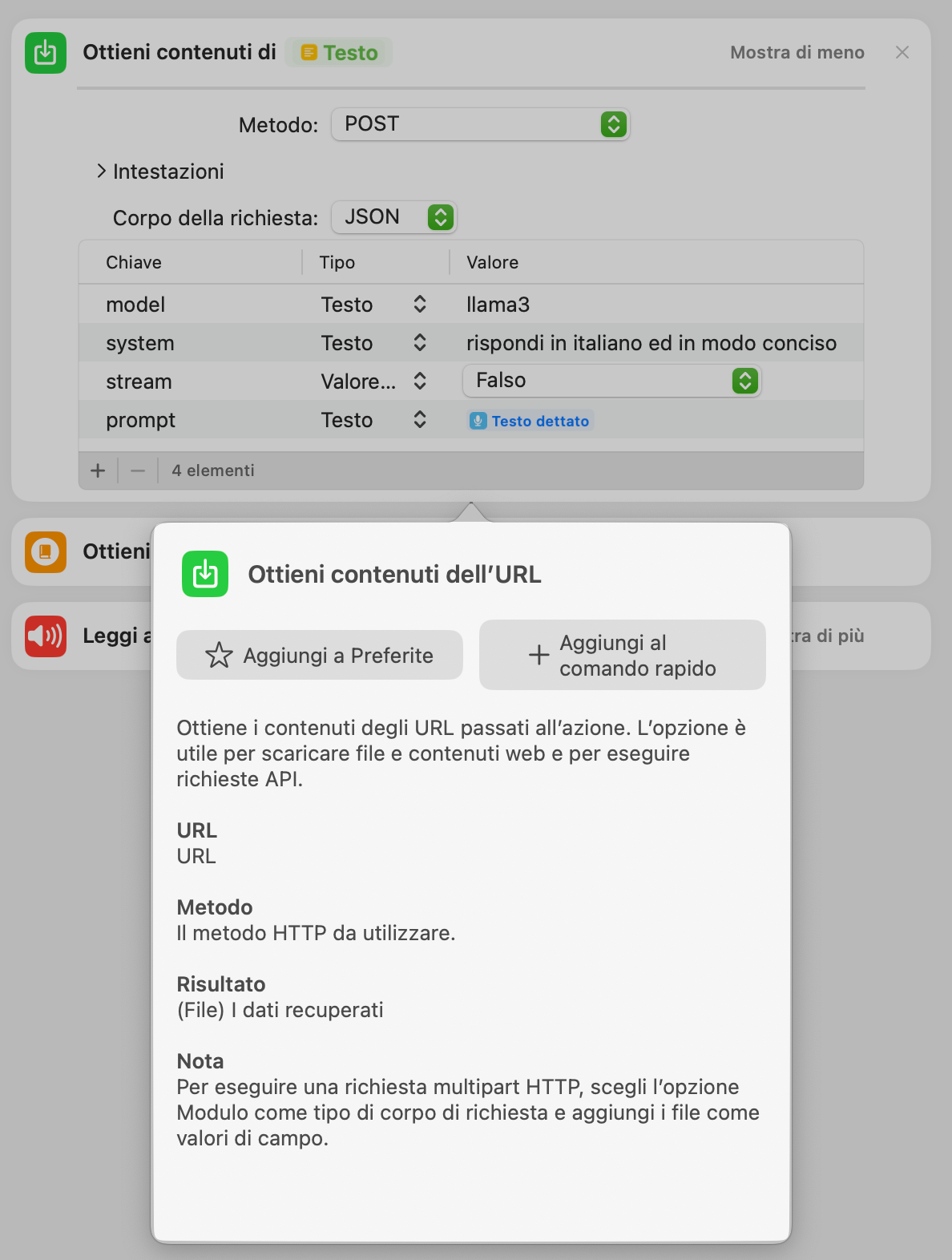
Informazioni sull’azione ottieni contenuti dell’URL
Questa azione permette di utilizzare sia il metodo GET che, per quanto riguarda noi, il metodo POST. Dobbiamo infatti porre la nostra domanda (il prompt) all’LLM attraverso Ollama.
La prima volta che si utilizza questa azione potresti rimanere perplesso perché una volta inserita nel nostro workflow l’azione è abbastanza anonima.

Esempio di azione ottieni contenuti dell’URL di base
Come si vede nell’immagine soprastante, al punto 1, occorrerà passare l’URL delle API della applicazione web; vedremo oltre come fare questo con Ollama.
Quello che ci interessa di più è premere sul tasto “mostra di più” (punto 2 dell’immagine soprastante).
Premendo sul pulsante ti verrà mostrata l’interfaccia completa dell’azione (come si vede nell’immagine sottostante).
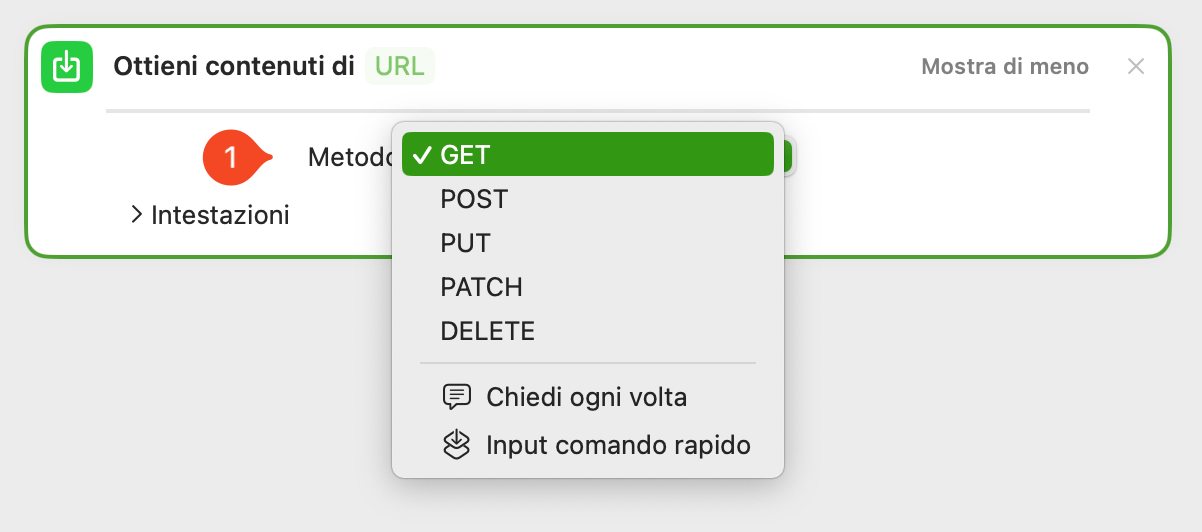
Scelta del metodo di accesso alle API
Cliccando sul pulsante metodo (punto 1 immagine soprastante), compariranno l’opzione che ci interessa: ovvero il metodo post. Selezionalo dal menù a tendina.
L’azione cambierà come mostrato nell’immagine sottostante.

Esempio di metodo post
Possiamo quindi comporre la nostra richiesta alle API di Ollama.
2.2 Un passo indietro: il funzionamento base delle API di Ollama
Qui trovi la documentazione ufficiale della API di Ollama. Nella documentazione sono indicati i parametri che possono essere richiesti alle API e vari esempi utilizzando il comando a terminale curl.
L’azione ottieni contenuti dell’URL, di fatto, sostituisce all’interno di Comandi Rapidi, il comando curl.
Per fare una richiesta ad Ollama occorrerà a livello minimo: specificare l’LLM che si vuole usare, indicare il prompt da sottoporgli.
Esistono poi due differenti modalità di interrogazione dell’LLM, con due differenti endpoint, ovvero punti di ingresso, delle API di Ollama:
- Generate, che serve per far generare una risposta da un prompt (quella che useremo noi) e
- completamento della Chat che invece serve per aver un dialogo con l’LLM e che non useremo / approfondiremo oggi.
2.3 L’URL delle API generative di Ollama
Possiamo quindi rispondere alla domanda iniziale: quale URL passare all’azione ottieni contenuto dell’URL.
Come si legge dalla documentazione in generate l’endpoint è /api/generate, a questo andrà anteposto l’URL di Ollama. Ma qual’è?
La risposta è doppia e, visto che questo è forse uno dei passaggi cruciali, cercherò di spiegartelo in modo dettagliato.
Piccola premessa: aprire dei servizi web all’esterno è pericoloso. Proprio per questo motivo Ollama, abitualmente, crea il suo punto di accesso in: http://localhost:11434.
localhostnel gergo tecnico dell’informatica è il computer stesso e si può accedere a tale indirizzo esclusivamente dal computer stesso.
In estrema sintesi se hai installato Ollama sul tuo Mac aprendo un qualsiasi browser e digitando http://localhost:11434 vedrai una cosa simile all’immagine sottostante e ti dimostrerà che Ollama è operativo sul tuo Mac. Se te lo stai domandando :11434è la porta di rete attraverso la quale è possibile accedere ad Ollama.
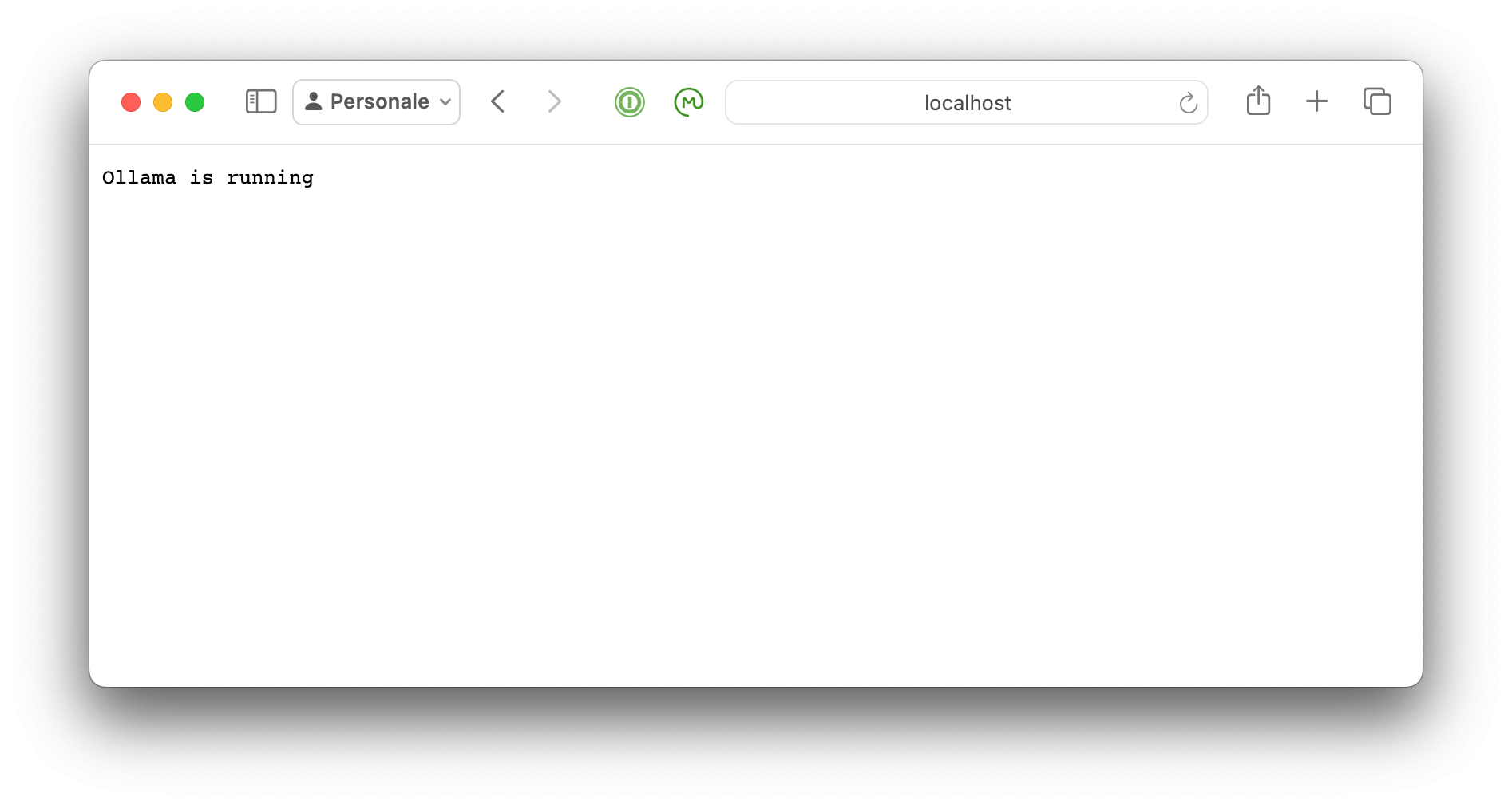
Esempio di accesso ad Ollama via localhost
Come ti dicevo, però, avere aperti dei servizi di rete non è la cosa più sicura, proprio per questo motivo Ollama non è configurato per permettere l'accesso dall’esterno (anche dalla rete intranet del tuo ufficio o della tua casa).
2.4 Configurare Ollama per accessi esterni
Quanto detto al punto precedente però è un problema. Infatti o lanci un comando rapido dal Mac su cui è installato Ollama o, altrimenti, non è possibile accedere alle API di Ollama.
Ecco che quindi può nascere la necessità di modificare la configurazione per permettere a tutti i dispositivi della tua rete. Questa necessità a me è venuta posto che attualmente lavoro su un iMac 27" Intel e su un MacBookPro 16" Intel ed ho comprato un MacStudio M1 proprio per avere un Mac che mi permettesse di fare tante cose con gli LLM.
La configurazione da fare è relativamente semplice ma occorrerà aprire una finestra di Terminale.
Fatto questo basta digitare il seguente comando:
launchctl setenv OLLAMA_HOST "0.0.0.0"Occorrerà poi uscire da Ollama e ri-lanciare l’applicazione perché la configurazione abbia effetto.
A questo punto sarà possibile accedere ad Ollama anche da un altro computer.
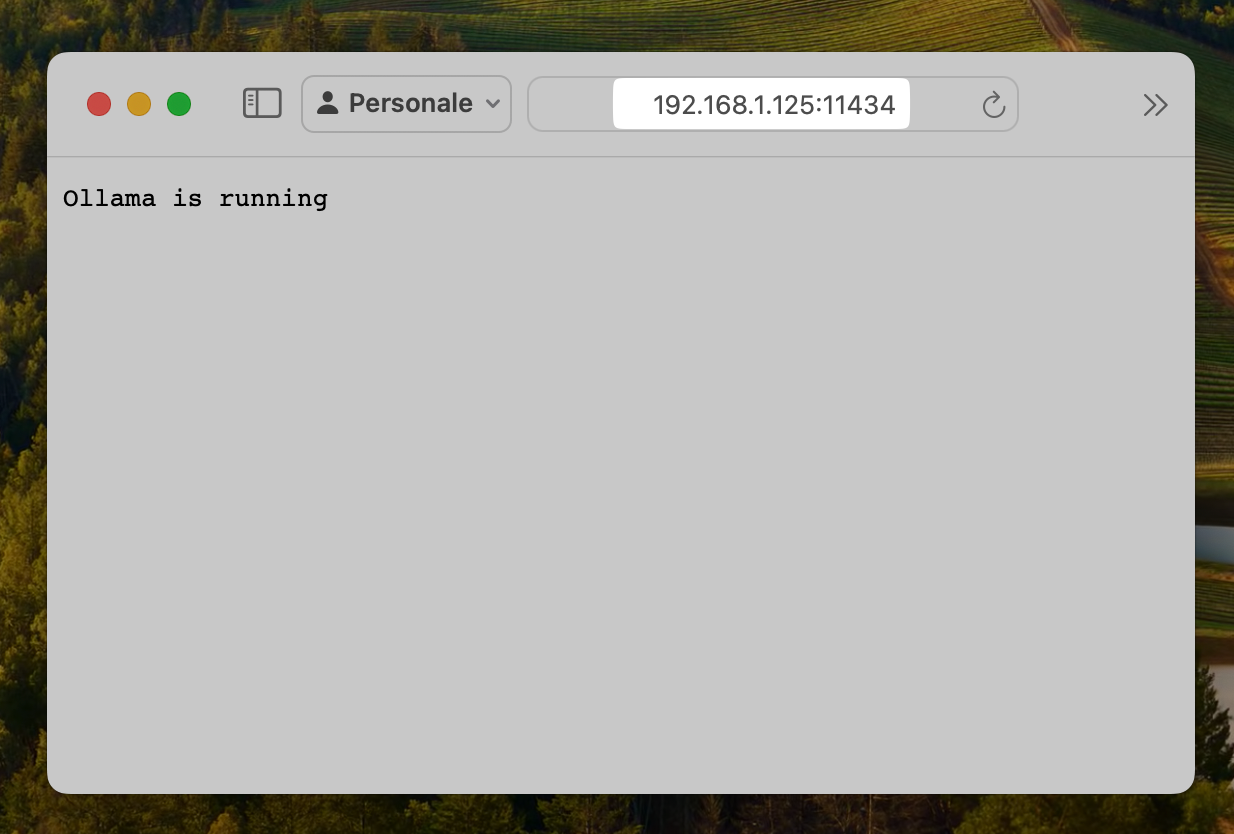
Esempio di accesso esterno ad Ollama: l’indirizzo IP è quello del mio MacStudio
Volendo è possibile anche accedere con il nome di rete del tuo Mac, nel mio caso http://macstudio.local:11434, come si vede nell’immagine sottostante.
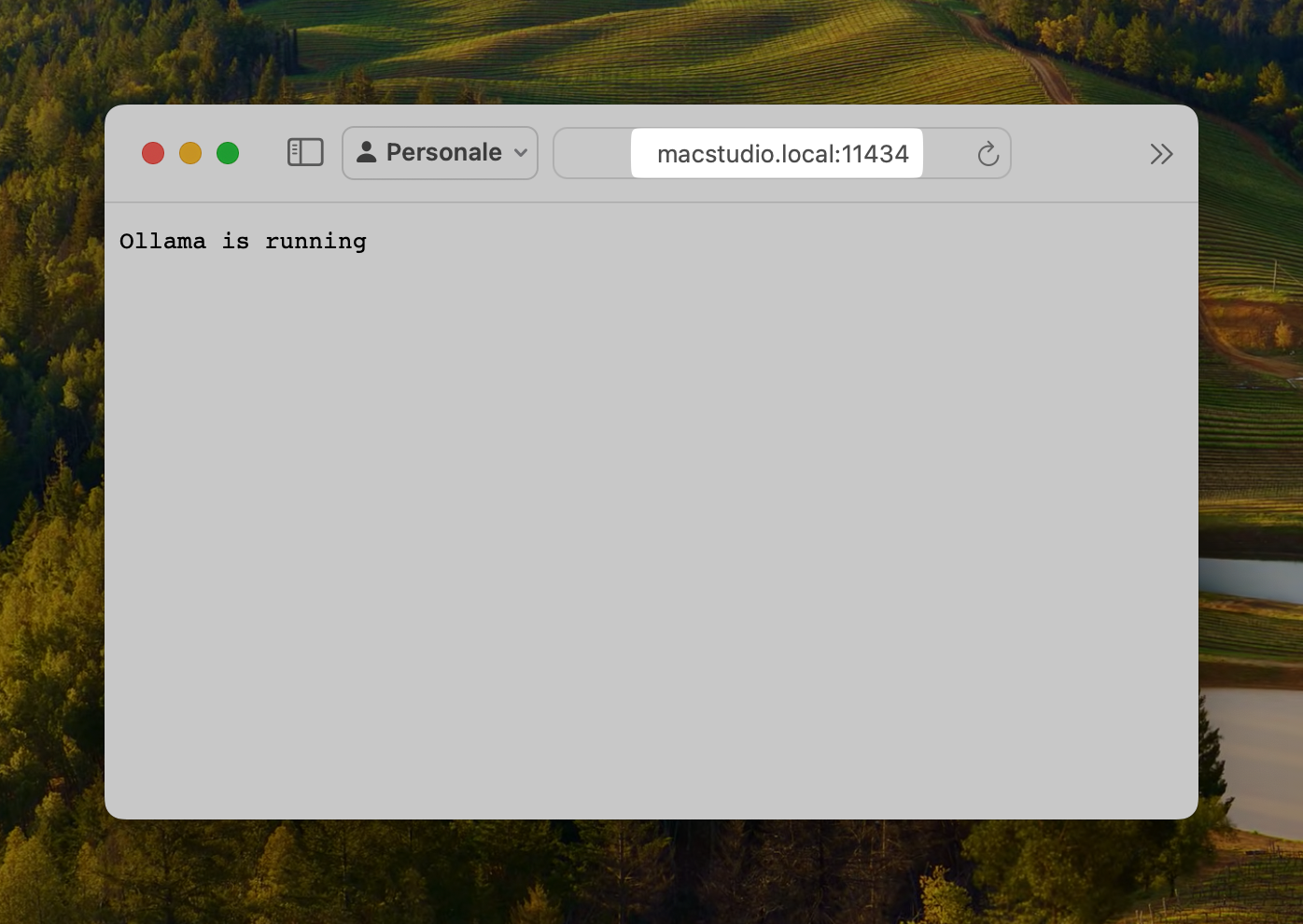
Esempio di accesso con il nome di rete del Mac
Qui trovi la guida di Apple su come trovare il nome e l’indirizzo di rete del tuo Mac.
2.5 Applichiamo tutto in Comandi Rapidi
Personalmente amo evitare di dover digitare l’URL direttamente dentro l’azione ed uso il trucco di un blocco testo dove inserisco l’url, come si vede nell’immagine sottostante.
Esempio di inserimento di URL delle API di Ollama
3. Interroghiamo le API di Ollama con il nostro comando rapido
Vediamo quindi come fare la richiesta alle API di Ollama.
Come ho scritto nei punti precedenti occorre, quantomeno, indicare il modello da utilizzare di LLM (in particolare il nome) ed il prompt.
Per fare questo dobbiamo inserire dei parametri all’interno della nostra richiesta POST. Per fare ciò clicca sul pulsante + come mostrato al punto 1 dell’immagine sottostante.
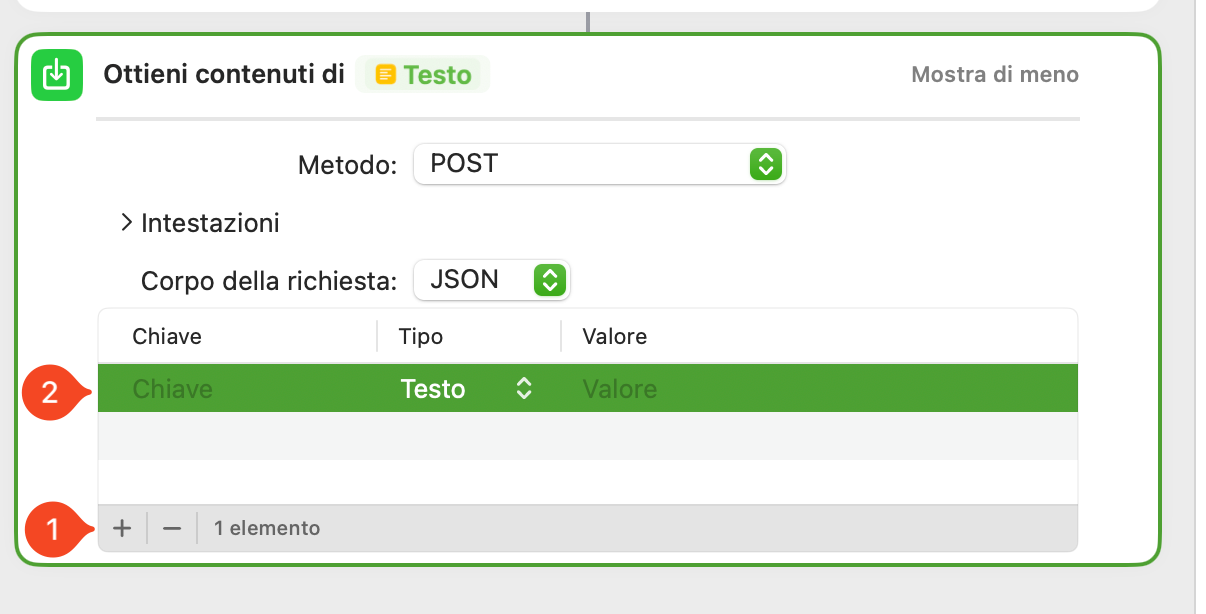
Inserimento parametri
Occorrerà inserire per ogni parametro una chiave (abitualmente il nome del parametro che vogliamo valorizzare), la tipologia del valore da passare al parametro, come si vede nell’immagine sottostante esistono diverse possibilità, ed infine il valore vero e proprio del parametro.
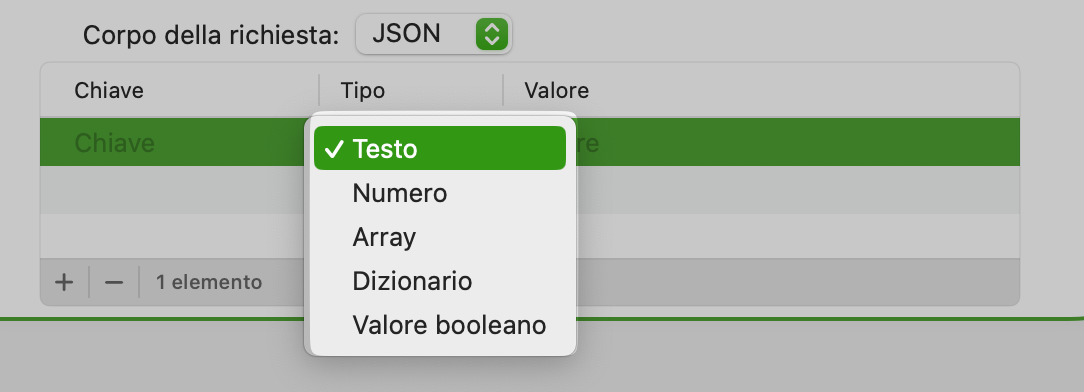
Tipologie dei valori dei parametri
La maggior parte delle tipologie dei valori è auto-esplicativa ma esamino velocemente le voci: Array, Dizionario e Valore booleano.
- Array: Si può immaginare un array come una sorta di contenitore, le cui caselle sono dette celle (o elementi) dell'array stesso. Ciascuna delle celle si comporta come una variabile tradizionale;
- Dizionario: Si può pensare ad un dizionario come ad una mappa tra due insiemi: il dominio è un insieme di chiavi, il codominio è un insieme di valori ad ognuna delle chiavi viene associato un valore un’associazione è detta coppia chiave-valore o anche elemento del dizionario;
- Valore Booleano: o vero o falso.
3.1 I parametri necessari
Il primo parametro necessario è il modello. La chiave quindi sarà "model" esaminando la documentazione delle API ed il valore è testuale (il nome del modello): ad esempio mistral. Lo segnalo solo per sicurezza … occorre preventivamente aver scaricato il modello altrimenti la chiamata alle API darà errore.
Secondariamente occorre inserire il testo del prompt. Ovvero chiave "prompt", tipo testo e valore il testo del prompt.
Infine, per semplificarci la vita, imposteremo il valore "stream" a falso, quindi come valore booleano. In questo modo la risposta dell’LLM arriverà in un unico flusso di testo e non in uno streaming di token che, poi, ci toccherebbe riunire in un testo di senso compiuto.
Piccola avvertenza su questo parametro. Se la risposta dell’LLM è molto grossa, ovvero il tempo per generare il testo finale è molto lungo, il comando rapido potrebbe dare un errore, infatti, se la risposta non arriva in un tot di secondi (credo circa 30) il comando darà un errore. Questo solitamente avviene quando il computer non riesce a gestire il modello e la risposta è lenta.
Di seguito ti mostro un esempio.
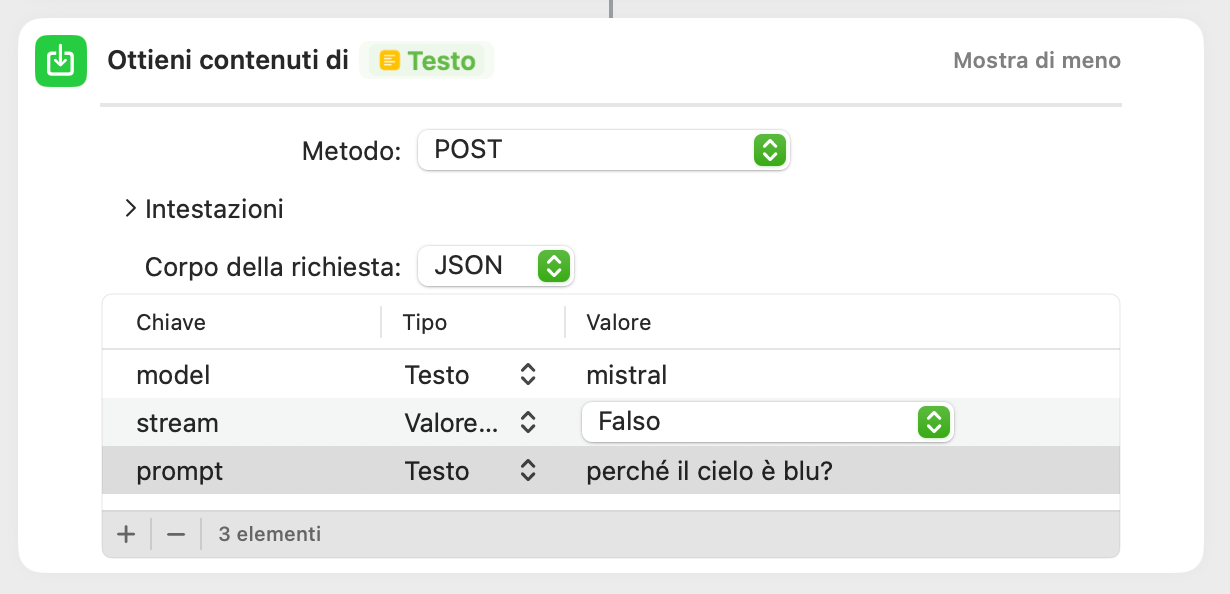
Esempio di valori
3.2 Parametri opzionali: Aumentare la finestra di contesto
Unica cosa che ti segnalo, perché può essere utile è come aumentare la finestra di contesto.
Infatti Ollama come impostazione di fabbrica ha una finestra di contesto di 2048 tokens.
Ricordo che i tokens non corrispondono 1 a 1 alle parole ma se si vuole fare dei conti al volo questa proporzione è un ottimo modo per valutare se il testo passato all’LLM supera o meno la finestra del contesto.
Come possiamo quindi aumentare la finestra del contesto?
Occorre utilizzare il parametro "options" che, tuttavia, richiede come valore un dizionario. In particolare all'interno del dizionario occorre inserire il parametro "num_ctx" (number of context, presumo, ovvero in italiano valore della finestra del contesto) ed il numero della dimensione del contesto.
Per fare questo occorrerà prima creare un nuovo elemento (tasto +) inserire il parametro e selezionare come tipo Dizionario. Fatto ciò è occorre poi aggiungere un nuovo elemento al dizionario con il parametro "num_ctx" come tipo "Numero" ed il valore del contesto; nel mio esempio raddoppio il contesto inserendo 4096, come si vede nell’immagine sottostante.

Esempio di parametri opzionali inseriti come dizionario
Se volessimo aggiungere altri parametri opzionali non dovremo fare altro che cercare il parametro nella documentazione delle API ed aggiungere un’altra voce del dizionario.
3.3 Risposta dell’LLM
Di seguito ti mostro la risposta dell’esempio precedente.

Il blob incomprensibile dell’LLM
Come potrai notare il risultato non è un gran che!
Se però andiamo ad esaminare la risposta completa (prendo l’icona dell’occhio, punto 1 immagine soprastante) la risposta c'è.

Anteprima risposta completa LLM
Il problema è che la risposta è cntenuta all'interno di un dizionario JSON assieme a mille altri dati.
A noi in particolare interessa la copia chiavi / valore: "response" : "testo della risposta …"
4. Estrarre la risposta delle API di Ollama
Arriviamo quindi alla fine di questo articolo e vediamo come estrarre il testo della risposta.
Il trucco è utilizzare l’azione Ottieni valore dizionario, come mostrato nell’immagine sottostante.

Esempio di ottieni valore dizionario
In particolare occorre valorizzare nel campo "Chiave" con il termine response, come mostrato nell’immagine sottostante.
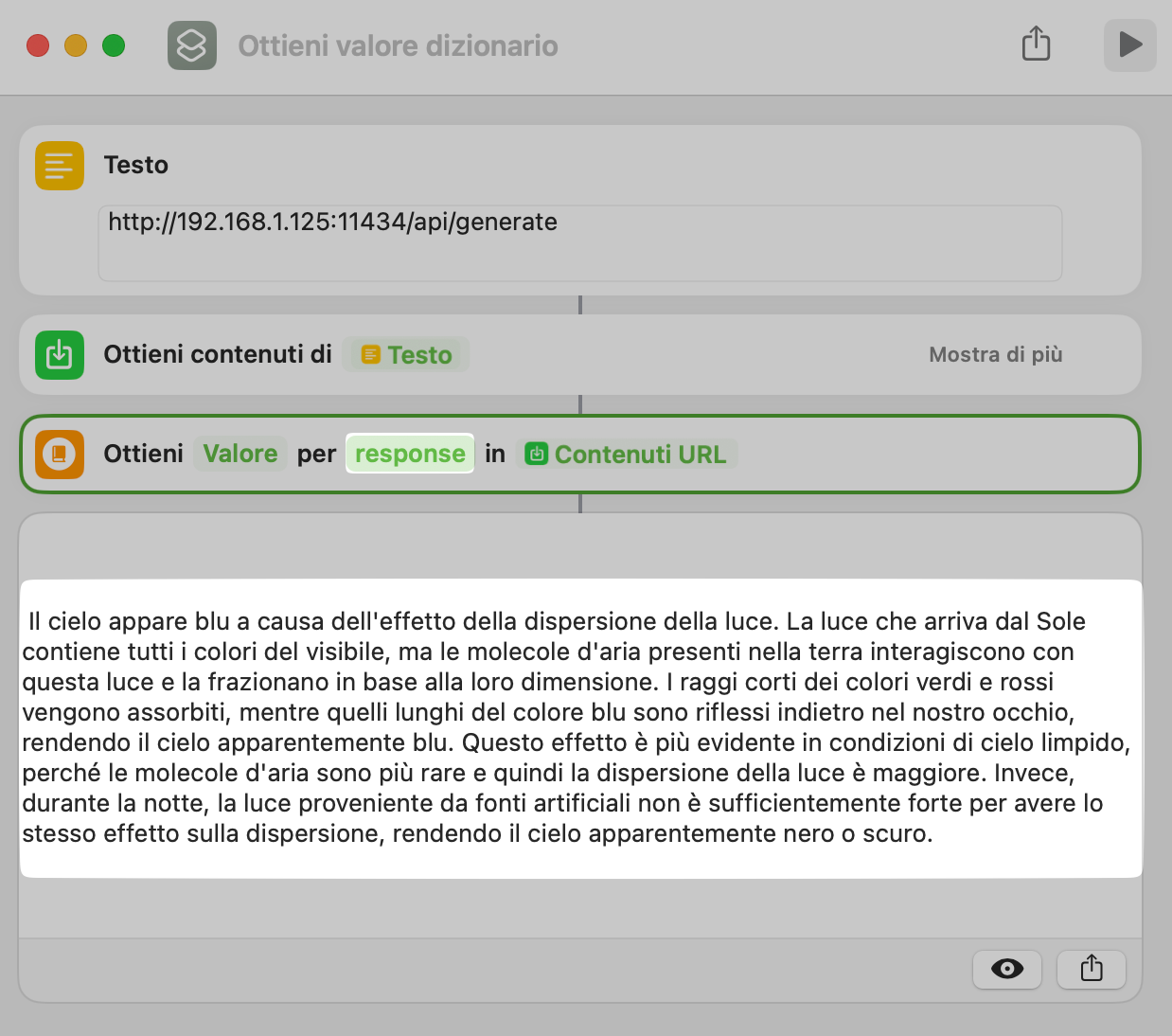
Esempio di estrazione della risposta dal dizionario
Così facendo si estrarrà la risposta dell’LLM.
Come potrai immaginare questa è la soluzione più semplice che si può implementare. Io ti consiglio di leggere i possibili parametri e sperimentare con richieste anche più complesse.
Inoltre, una volta capito il sistema, è possibile implementare la potenza di Comandi Rapidi con quella dei Large Language Model.
5. Semplice esempio di cosa è possibile fare con Comandi Rapidi
Di seguito ti mostro un semplice comando rapido che prende l’input dalla voce, la converte in testo, passa il testo all’LLM e, una volta ricevuta la risposta, la legge con la voce di Siri.
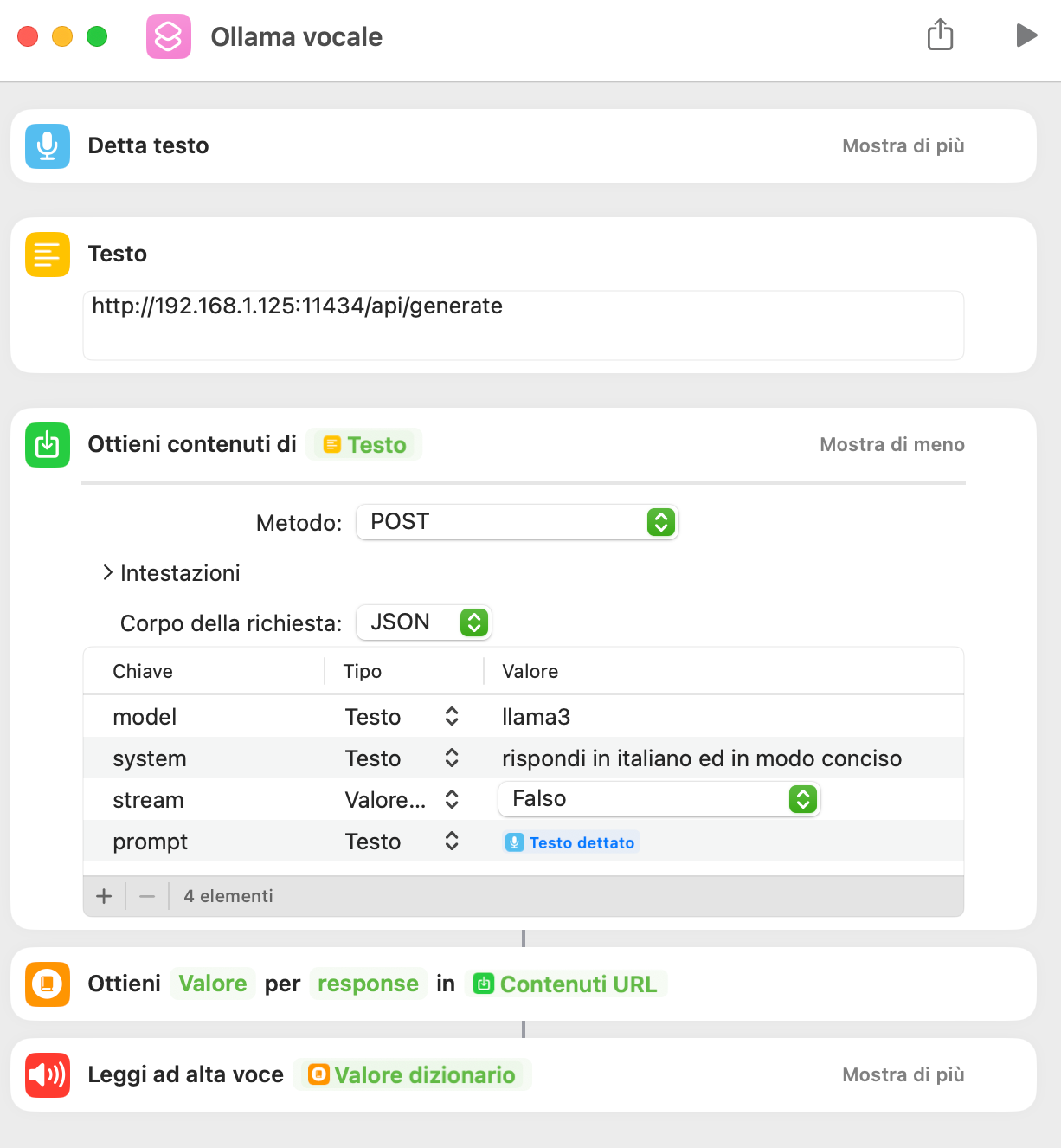
Esempio di comando rapido che utilizza LLM e le azioni di Comandi Rapidi
Come sempre la fantasia e le necessità dell’utente sono il limite!
6. Nota finale
Questo articolo, anche se spiega nel dettaglio come utilizzare le API di Ollama in Comandi Rapidi, può essere usato – con le dovute accortezze – per interfacciarsi a qualsiasi API.
In conclusione
Non pensavo che l’articolo diventasse così lungo ma la gestione delle chiamate alle API richiede effettivamente un minimo di spiegazione. La mia non è super esaustiva ma spero ti dia le basi per poter lavorarci ed eventualmente approfondire.
Ulteriormente abbiamo visto come è possibile utilizzare Comandi Rapidi per interfacciarsi con le API; sicuramente un argomento avanzato ma utile da conoscere. Nel panorama attuale infatti potersi interfacciare con le API delle applicazioni web è una risorsa molto utile e, forse, necessaria.
Ho scritto questo articolo per porre le basi per creare comandi rapidi più evoluti (che ho già fatto) e per permettermi, in futuro, di mostrarti alcune interessanti soluzioni per implementare gli LLM nel tuo flusso di lavoro.
Come sempre, se ti è piaciuto quel che hai letto o visto e non l’hai già fatto, ti suggerisco di iscriverti alla mia newsletter. Ti avvertirò dei nuovi articoli che pubblico (oltre ai podcast e video su YouTube) e, mensilmente, ti segnalerò articoli che ho raccolto nel corso del mese ed ho ritenuto interessanti.