
L'integrazione dell’Intelligenza Artificiale in uno studio legale usando un MacMini M1: vantaggi e sfide
Da inizio 2024 ho dedicato molto del mio tempo libero ad approfondire l’argomento della c.d. Intelligenza Artificiale generativa.
Ne ha anche recentemente parlato nella mia ultima OfficeHour del 25 Gennaio 2024 e che ti consiglio di guardare per avere maggiori informazioni sull’argomento.
Fino a fine Febbraio gli esperimenti che ho condotto erano prevalentemente con chatGPT; il 26 febbraio 2024 ho provato con successo un approccio differente che, secondo me, apre nuovi spazi per gli avvocati: l’utilizzo di LLM offline su un proprio computer.
In particolare ho fatto i primi, positivi, esperimenti con Ollama e Mistral sul mio Mac Mini M1 con 8 Gb di Ram unificata. Ho fatto un rendiconto dettagliato nella mia ultima newsletter.
Questo articolo descrive i passi che ho fatto e ti permetterà, se lo vorrai, di provare a tua volta.
1. L’hardware necessario
Gli LLM o Large Language Model sono modelli semantici che permettono, a fronte di una richiesta o prompt, di generare testo.
Se originariamente la creazione ed il funzionamento di simili motori era appannaggio solo di grandi aziende con enorme potere computazionale a disposizione (delle intere server farm) nell’ultimo anno si è vista la nascita di progetti di ricerca e non solo di modelli che richiedono molta meno potenza. Se inizialmente era necessaria una enorme server farm di computer ora è possibile far girare sul proprio computer dei modelli di LLM.
Il vantaggio di questa soluzione, per l’avvocato, è che i dati passati all’LLM non devono andare su server gestiti, non si sa come, da altri. Come ho detto nella mio corso PCT, a livello deontologico oltre che per il GDPR, l’avvocato ha degli specifici obblighi deontologici di segretezza e riservatezza.
Lo svantaggio di questa soluzione è che occorre dell’hardware specializzato. In particolare i modelli richiedono grosse quantità di VRAM la memoria delle GPU. Questo significa che il proprio PC deve essere dotato di una scheda grafica importante (solitamente del brand NVIDIA) e con almeno 8 fino a 64 Gb di RAM. Per gli utenti Apple possessori dei computer con i nuovi CHIP Apple, tuttavia, c’è una buona notizia: grazie alla nuova architettura del processore la RAM del computer è “unificata” ovvero a disposizione sia della CPU che della GPU e si può testare gli LLM open-source.
Detto in parole povere se hai un Mac con Apple Silicon con 8Gb di RAM, il taglio minimo, puoi utilizzare la RAM del tuo Mac per farci girare un LLM di piccole dimensioni, ovviamente. Se addirittura sei un possessore di un Mac con Apple Silicon con dei tagli più generosi di RAM (almeno 32 Gb) ti si aprono notevoli possibilità con gli LLM offline.
Purtroppo ho solo un Mac con Apple Silicon: un MacMini M1 di prima generazione con 8Gb di RAM.
2. La mia fortunata scoperta
Nel corso del 2023 avevo già provato a far girare sul mio MacMini offline alcuni LLM open-source ma i risultati erano stati a dir poco mediocri; nella migliore delle ipotesi infatti la generazione del testo avveniva in modo così lento che tra una richiesta e l’altra passavano decine di minuti.
Il mondo degli LLM open-source tuttavia è in continuo fermento e nel weekend precedente al 26 Febbraio ho provato a fare dei nuovi esperimenti che, questa volta, mi hanno portato a risultati soddisfacenti.
Questo mi ha portato nel corso di questo periodo a fare svariati approfondimenti e test di cui, se c’è interesse, voglio parlarti in futuro.

Esempio degli appunti recenti sull’argomento che ho preso in Obsidian
Ciò detto, ti preavviso, se vuoi replicare anche tu con un Mac simile al mio dovrai comunque sottoporti a tante limitazioni. Pur non avendo ancora fatto dei test concreti sono convinto che sia necessario per l’utilizzo di modelli più performanti l’utilizzo di un Mac con almeno 32Gb di RAM, sto chiedendo ad amici che hanno un Mac Studio con 32Gb di RAM di farli per me.
Fatte queste dovute premesse vediamo come è possibile avere un LLM personale ed offline per sperimentare di prima mano ed in modo sicuro con l’Intelligenza Artificiale generativa.
3. I software necessari per testare un LLM privato ed offline
Lavorare con i modelli open-source di LLM inizialmente richiedeva notevoli competenze informatiche. Nella “democratizzazione” di questi software, progressivamente si è assistito ad una notevole semplificazione delle attività necessarie per utilizzare questi strumenti. Ciò detto ti segnalo che è comunque necessaria un minimo di competenza anche se, come protrai vedere oltre, i passi non sono così complessi (altrimenti non ci sarei riuscito nemmeno io).
3.1 Cos’è Ollama?
Ollama è un progetto open-source che rende veloce installare un ambiente per testare i modelli di LLM open-source che, nel tempo sono stati creati. Ollama inoltre permette di interfacciarsi in modo semplice con gli LLM.
È possibile scaricarlo come app per Mac, Windows ed installarlo con uno script da terminale per Linux.
Per macOS una volta scaricato, installato ed avviato (trovi Ollama nelle cartella delle applicazioni di macOS), ti trovi una icona sulla barra dei menù di macOS a forma di Lama e cliccandoci sopra è possibile chiudere l’applicazione.

Esempio di come si mostra Ollama dopo averlo lanciato
Oltre a poter interagire con il modello di LLM (da scaricare a parte) Ollama permette di utilizzare i modelli via API. La gestione delle API è complessa e la si trova qui.
3.2 Cos’è il comando LLM?
Come vedremo dopo è possibile installare svariati tipi di LLM via Ollama ed interfacciarsi con essi via Terminale. Tuttavia se si vuole sfruttare meglio gli LLM (come ti mostrerò alla fine di questo articolo) è necessario aver la possibilità di passare informazioni.
Proprio per evitare di interfacciarsi con le API e non avere solo la chat a terminale, viene in soccorso il comando llm (sito del progetto).
llm è un’utilità CLI (interfaccia a riga di comando) e una libreria Python per interagire con i modelli di linguaggio di grandi dimensioni, sia tramite API remote che modelli che possono essere installati ed eseguiti sulla propria macchina.
Sviluppata da Simon Willison per le API di OpenAI, grazie alla sua integrazione con altri sistemi (attraverso plugin) è possibile utilizzare il comando per interagire con Ollama ed i modelli che sono stati scaricati con questo sistema.
Questo, come si vedrà oltre, permette di passare all’LLM documenti e pagine web senza troppi problemi.
3.3 Il modello LLM Mistral
L’ultima tessera del puzzle è un modello LLM che possa funzionare decentemente offline. Molti modelli infatti sono sì performanti ma richiedono caratteristiche hardware importanti.
Mistral 7b è un modello relativamente leggero ed open-source che può essere usato localmente. È sviluppato da una società francese e, tra i suoi pregi, ha che è stato istruito anche in lingua italiana; uno dei problemi maggiori con i modelli open-source è che sono stati istruiti prevalentemente in lingua inglese e quindi si prestano poco alle esigenze di un avvocato o utente italiano.
3.4 I limiti di Mistral
Anche se Mistral può parlare in italiano, tendenzialmente “parla” in inglese …
Può, tuttavia, essere “forzato” a parlare in italiano via prompt ma non funziona sempre (non ho trovato un modo univoco di ottenere il risultato – abitualmente tuttavia se ci mette molto a generare l’output vuol dire che sta lavorando in inglese).
4. Installazione dei software
Vediamo come installare tutto il necessario sul nostro Mac con Apple Silicon.
Per Ollama è possibile scaricare direttamente il DMG dalla pagina del progetto ma io preferisco da sempre utilizzare HomeBrew. Se non sai cos’è, come installarlo ed usarlo, ti segnalo questo mio articolo in cui ne parlo. Per alcuni comandi da terminale, poi, è necessario usare pip; pip è un gestori di pacchetti per Python.
Tornando all’articolo, ho installato il tutto via HomeBrew utilizzando il comando a terminale:
brew install --cask ollamaPoi ho installato Mistral; ho provato anche altri LLM ma Mistral, allo stato, è quello che funziona meglio (risposte relativamente veloci) sull’M1.
Utilizzando il comando sottostante, verrà scaricato il modello di Mistral (circa 4Gb) e si aprirà la chat. In dipendenza dalla tua connessione internet questo passo può richiedere anche molto tempo.
ollama run mistralPotenzialmente qui ti puoi fermare, perché finito il download, ti troverai con la possibilità di chattare con Mistral.

Esempio di chat con Mistral via Terminale sul mio MacMini M1
Per uscire dalla chat occorre digitare /bye o premere la scorciatoia a tastiera CTRL+D.
Ho poi utilizzato il programma a riga di comando llm (progetto che si trova qui), installato sempre via HomeBrew.
brew install llmHo aggiunto l’integrazione (plugin) che permette di utilizzare llm con Ollama:
llm install llm-ollamaFatto ciò sei pronto ad interagire via Terminale con Mistral; digitando a riga di comando un comando simile a questo:
llm -m mistral "prompt al LLM"
Esempio di richiesta a Mistral usando il comando llm
Se volessi usare la chat invece devi usare il seguente comando:
llm chat -m mistral
Esempio di chat via llm con Mistral
5. Usare Mistral ed llm per riassumere un PDF
Per far quanto mostrato sopra non ha molto senso usare il comando llm; tuttavia se si vogliono fare delle cose più interessanti allora questo comando inizia a diventare molto utile.
Non è mia intenzione approfondire troppo questa parte ma voglio farti vedere come sia possibile utilizzare llm per fare cose che, abitualmente, non sono fattibili in modo facile e veloce con un modello LLM che funzioni come chat.
Ti segnalo, se ti interessa, che sono anche riuscito a utilizzare Ollama attraverso una interfaccia grafica web che, di fatto, ricrea un chatGPT. Tuttavia esula dagli scopi di questo iniziale guida e, se ci sarà interesse, ne parlerò in un futuro articolo.
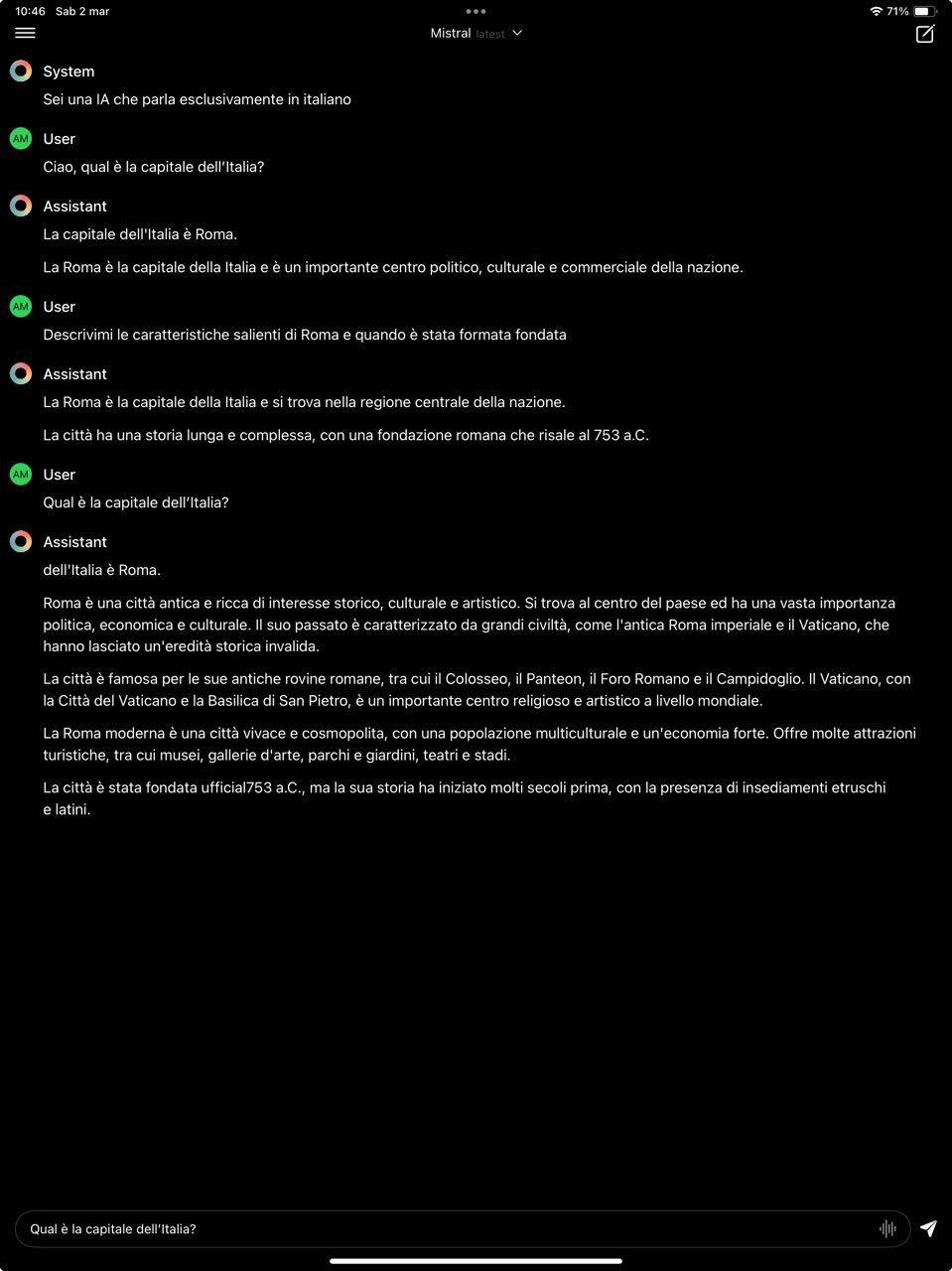
Esempio di chat su iPad con Mistral e l’app Enchanted LLM
5.1 Convertire un PDF in testo semplice
Anzitutto per poter lavorare con i PDF occorre convertire il PDF in testo semplice. Per fare ciò esistono svariate soluzioni, io dopo alcune ricerche ho installato poppler via HomeBrew:
brew install popplerGrazie a questo comando (che installa varie utility da terminale) è possibile utilizzare il comando pdftotext per la conversione:
pdftotext -enc UTF-8 input.pdf output.txtSintetizzando molto, il comando soprastante prevede la conversione del testo in formato UTF-8-enc UTF-8 poi si passa il file che si vuole convertire, nell’esempio input.pdf ma il nome del file può essere arbitrario, se utilizzi un file con degli spazi nel nome ti ricordo di utilizzarlo tra virgolette ad esempio: "PDF da convertire.pdf".
Altro trucco da tenere presente, se non sei un esperto del terminale, è l’auto-completamento, che si attiva digitando la parte iniziale del nome del file e poi premendo il tasto TAB, se il completamento è univoco (non ci sono altri file con nome che inizia con gli stessi caratteri) il nome del file verrà completato automaticamente, altrimenti verranno suggerite le opzioni e si dovrà aggiungere uno o più caratteri e premere nuovamente TAB.
Infine il output.txt è il nome del file convertito in formato testo che si vuole creare.
5.2 Passare il testo all’LLM
Fatta questa operazione preliminare si può creare il comando che ci permetterà di fare “magie” con il nostro LLM.
Via terminali si usa il pipe (tubo di congiunzione dei comandi a terminale) utilizzando il simbolo |. Nel comando sottostante ho estratto il testo del file .txt e l’ho girato al comando llm
cat output.txt | llm -m mistral "riassumi il testo in circa 400 parole, utilizza la lingua italiana per il riassunto"La risposta dell’LLM verrà “stampata” a terminale.
Se si vuole avere il tutto in un file, il comando va modificato come segue:
cat output.txt | llm -m mistral "riassumi il testo in circa 400 parole, utilizza la lingua italiana per il riassunto" >> "risposta LLM.txt"Il doppio segno maggiore dice di inviare l’output del comando a terminale al file indicato, nel mio caso risposta LLM.txt (messo tra virgolette perché ci sono degli spazi ed il terminale altrimenti non li gestisce). Il > sovrascrive il contenuto del file (se già presente) il semplice >> salva in coda (append) al file di testo.
6. Passare pagine web all’LLM
Per ampliare la “conoscenza” del nostro LLM è possibile passargli una pagina internet.
6.1 Installazione di strip-tags e ttok
La prima cosa che consiglio di fare è installare 2 programmi da riga di comando sempre di Simon Willison.
pip install ttokttok è installabile anche via homebrew con il comando: brew install ttok
pip install strip-tagsI 2 comandi fanno le seguenti cose:
- ttok: da il conteggio dei token di un determinato testo o, se si utilizza il parametro
-ttronca (t sta per truncate in inglese) il testo; gli LLM hanno una c.d. finestra massima ovvero una quantità massima di testo (token sarebbe più corretto dire perché un token non corrisponde ad una lettera) con cui possono lavorare, con input di grosse dimensioni è opportuno tagliare l’input o utilizzare differenti tecniche per passare i dati all’LLM; - strip-tags: pulisce l’html della pagina web, per avere un input più chiaro per l’LLM, il parametro che suggerisco di usare è
-mche sta per minify per ridurre al minimo gli spazi bianchi – riducendo più spazi e caratteri di tabulazione a un singolo spazio e più nuove righe e spazi a un massimo di due nuove righe.
6.2 Comando per passare una pagina web all’LLM
Di seguito mostro un esempio di comando per passare una pagina web all’LLM (se vuoi vedere la pagina web originale segui questo link:
curl -s https://www.avvocati-e-mac.it/blog/2024/1/24/llm-per-avvocati-25-gennaio-2024-ore-1400 | strip-tags -m | llm -m mistral "riassumi il contenuto del testo in 400 parole rispondendo esclusivamente in lingua italiana"Il primo comando curl serve per scaricare una specifica pagina web, l’opzione -s per non stampare a terminale l’output ma passarlo al comando successivo, ovviamente a seguire c’è l’URL della pagina web che si vuole passare all’LLM. Ho utilizzato strip-tags -m per togliere i tag HTML della pagina e ridurre spazi bianchi ed altro e, poi, passato il risultato finale all’LLM con un prompt per riassumere il contenuto.
Quello che segue è il testo ottenuto a terminale:
Il testo presenta una notizia relativa all'Organizzazione di un evento intitolato "OfficeHour" condotto da Filippo Strozzi il giovedì 25 Gennaio 2024 dalle 14:00 alle 15:00. In questo evento, Filippo spiegherà i concetti di Intelligenza Artificiale (IA) e dei Large Language Models (LLM), come ChatGPT, smentendo alcuni miti su queste tecnologie. Saranno esplorate le utilità di tali strumenti per gli avvocati ed i precauzioni che dovrebbero essere presi prima di fornire ai sistemi IA dati dei propri clienti. Il video della diretta sarà successivamente reperibile per la consultazione futura.
6.3 Esempio pratico
Ma perché passare una pagina web o un testo all’LLM potrebbe essere utile?
La risposta è relativamente semplice: gli LLM generalisti ed in particolare quelli offline non conoscono ad esempio il diritto italiano, passare un testo che spieghi in dettaglio i concetti giuridici permette all’LLM di “imparare” (sarebbe meglio dire avere un dato statistico più preciso delle parole che descrivono uno specifico aspetto giuridico) e quindi dare risposte più centrate.
Nell’immagine sottostante ti mostro cosa voglio dire. Puoi infatti vedere differenti risposte dell’LLM a fronte di informazioni che gli ho passato.
L’attività che ho svolto, nel linguaggio delle IA, viene definita RAG. RAG è un quadro di intelligenza artificiale per recuperare i fatti da una base di conoscenze esterna per basare i modelli linguistici di grandi dimensioni (LLM) sulle informazioni più accurate e aggiornate e per fornire agli utenti informazioni sul processo generativo degli LLM.
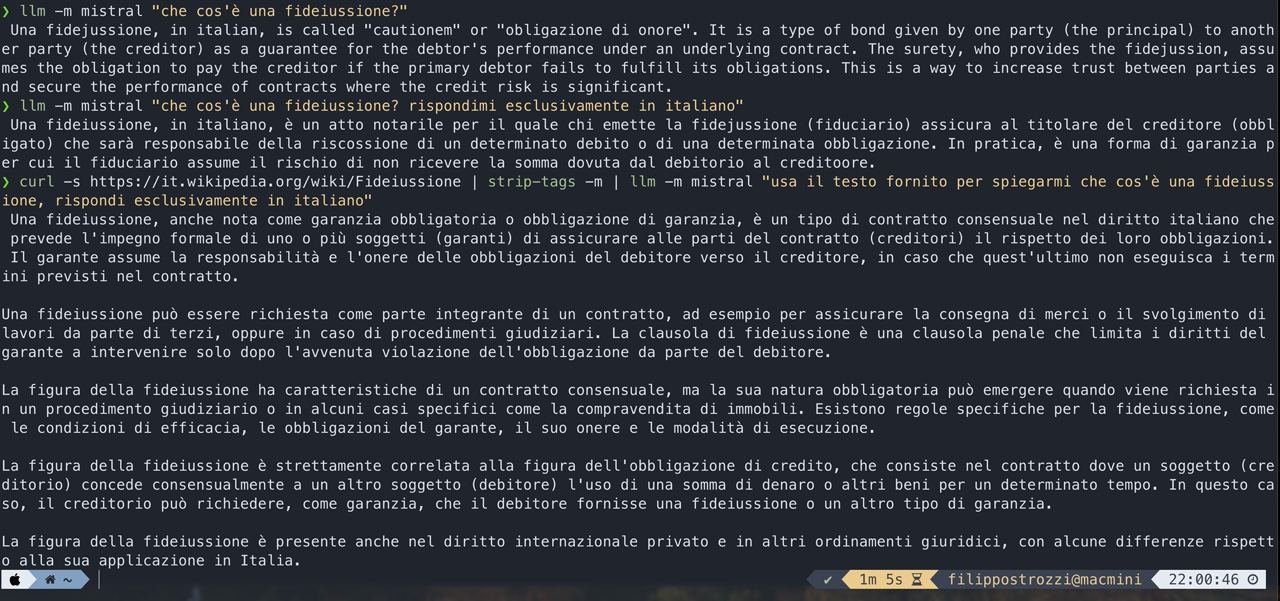
Esempio di RAG e delle suo potenzialità per il mondo legale
In conclusione
Spero di non aver messo troppa carne al fuoco ma volevo farti capire le possibilità di questo sistema anche se non ti ho fatto vedere cose eclatanti.
Ti suggerisco di provare a testare, se hai a disposizione un Mac con Apple Silicon, quanto ti ho mostrato. Credo infatti che solo sporcandosi realmente le mani con gli LLM si possa veramente comprendere le potenzialità ma soprattutto il limiti di questi sistemi.
Volendo sintetizzare, ti ho mostrato come andare oltre al semplice prompt di un LLM ma anche come, per avere dei risultati sensati nel mondo giuridico italiano, si ancora necessario un lavoro complesso e non per tutti. Ciò detto, con le dovute competenze interdisciplinari e voglia di sperimentare, è possibile ottenere risultati interessanti e soprattutto in conformità ai doveri deontologici dell’avvocato (di riservatezza e segretezza).
Come sempre se ti è piaciuto quel che hai letto e non l’hai già fatto ti suggerisco di iscriverti alla mia newsletter. Ti avvertirò dei nuovi articoli che pubblico (oltre ai podcast e video su YouTube) ed una volta al mese ti segnalerò articoli che ho raccolto nel corso del mese ed ho ritenuto interessanti.